I recently read a blog post about issues with writing purely functional code in Scala. The post talked a bit about a paper addressing tail-recursion in Scala. The code example (taken from the paper) was an implementation of zip lists, called zipIndex, that was not properly tail-recursive and would result in a stack overflow for relatively small inputs. A later post from the author will look at ways of addressing the problem and I’m looking forward to reading about it.
I’m assuming the next post will do something similar to the tail-recursive factorial function.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| def factorial(n: BigInt): BigInt = { | |
| def fact(n: BigInt, result: BigInt): BigInt = { | |
| if (n == 0) return result | |
| else return fact(n – 1, result * n) | |
| } | |
| return fact(n, 1) | |
| } |
I’d write a zip list in much the same way:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| // Scala analog to Clojure's loop-recur construct | |
| def loopRecur[A](index: Int, coll: Seq[A], zippedList: List[(Int, A)]): List[(Int, A)] = { | |
| if (coll.isEmpty) return zippedList | |
| else return loopRecur(index + 1, coll.tail, zippedList ++ List((index, coll.head))) | |
| } | |
| // Given a sequecne of items, returns a List of tuples of the form (item index, item) | |
| def zipIndex[A](coll: Seq[A]): List[(Int, A)] = { | |
| return loopRecur(0, coll, List.empty[(Int, A)]) | |
| } |
The recursion is handled with a function called loopRecur, the name of which was inspired by Clojure’s loop and recur forms. I’ve tested the above implementation of zipIndex with inputs of up to 100,000 elements. If this were in Clojure, the code would run much faster than the Scala.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| (defn zipIndex [coll] | |
| (loop [list coll | |
| n 0 | |
| result []] | |
| (if (empty? list) | |
| result | |
| (recur (rest list) (inc n) (conj result [n (first list)]))))) |
To test the Clojure, assuming you have access to a Clojure REPL, you can run (zipList (range 100000)) and then be amazed at how much faster the Clojure version runs compared to the Scala.

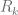 . The number of 0s to the left of site k is
. The number of 0s to the left of site k is  . Note that if
. Note that if  , then
, then 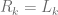 .
.